Column arithmetic and creation¶
Watch it
See the accompanied youtube video at the link here.
Doing some sort of transformation on the columns of a dataframe will most likely come up in your analysis somewhere and it’s not always straightforward.
Let’s welcome back the cereal.csv data we have been working with.
cereal = pd.read_csv('cereal.csv')
cereal.head()
| name | mfr | type | calories | protein | fat | sodium | ... | sugars | potass | vitamins | shelf | weight | cups | rating | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100% Bran | N | Cold | 70 | 4 | 1 | 130 | ... | 6 | 280 | 25 | 3 | 1.0 | 0.33 | 68.402973 |
| 1 | 100% Natural Bran | Q | Cold | 120 | 3 | 5 | 15 | ... | 8 | 135 | 0 | 3 | 1.0 | 1.00 | 33.983679 |
| 2 | All-Bran | K | Cold | 70 | 4 | 1 | 260 | ... | 5 | 320 | 25 | 3 | 1.0 | 0.33 | 59.425505 |
| 3 | All-Bran with Extra Fiber | K | Cold | 50 | 4 | 0 | 140 | ... | 0 | 330 | 25 | 3 | 1.0 | 0.50 | 93.704912 |
| 4 | Almond Delight | R | Cold | 110 | 2 | 2 | 200 | ... | 8 | 1 | 25 | 3 | 1.0 | 0.75 | 34.384843 |
5 rows × 16 columns
Attribution:
“80 Cereals” (c) by
Chris Crawford is licensed
under Creative Commons Attribution-ShareAlike 3.0
Unported
To make things especially clear, for the next few scenarios let’s only use the first 5 rows of the dataset.
cereal= cereal.iloc[:5]
cereal
| name | mfr | type | calories | protein | fat | sodium | ... | sugars | potass | vitamins | shelf | weight | cups | rating | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100% Bran | N | Cold | 70 | 4 | 1 | 130 | ... | 6 | 280 | 25 | 3 | 1.0 | 0.33 | 68.402973 |
| 1 | 100% Natural Bran | Q | Cold | 120 | 3 | 5 | 15 | ... | 8 | 135 | 0 | 3 | 1.0 | 1.00 | 33.983679 |
| 2 | All-Bran | K | Cold | 70 | 4 | 1 | 260 | ... | 5 | 320 | 25 | 3 | 1.0 | 0.33 | 59.425505 |
| 3 | All-Bran with Extra Fiber | K | Cold | 50 | 4 | 0 | 140 | ... | 0 | 330 | 25 | 3 | 1.0 | 0.50 | 93.704912 |
| 4 | Almond Delight | R | Cold | 110 | 2 | 2 | 200 | ... | 8 | 1 | 25 | 3 | 1.0 | 0.75 | 34.384843 |
5 rows × 16 columns
Take this next scenario.
Perhaps we recently read the cereal data’s documentation explaining that
the fat column is being expressed as grams and we are interested in
milligrams.
How can we rectify this?
We need to multiply each of the row’s fat values by 1000.
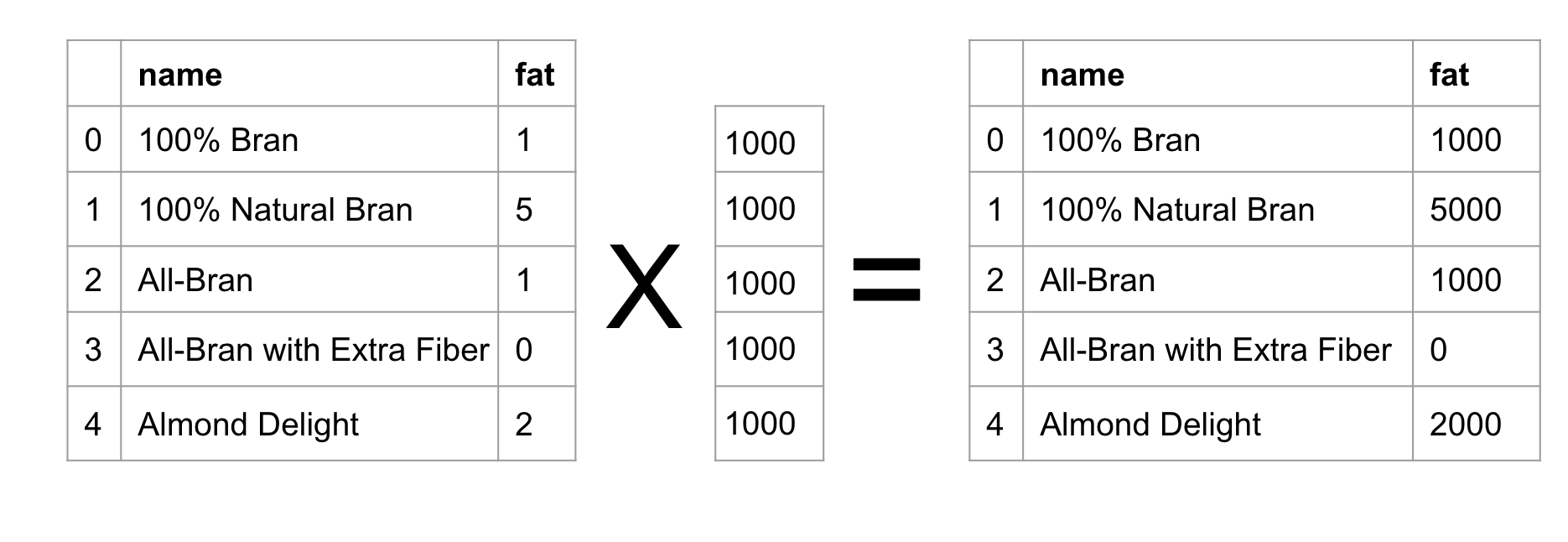
Here is where some magic happens.
Python doesn’t require us to make a whole column filled with 1000s to get the result we want.
It simply multiplies each value by 1000. (In Python we use * for
multiplication.)
So our original fat column in the cereal dataframe is transformed from this:
cereal['fat']
0 1
1 5
2 1
3 0
4 2
Name: fat, dtype: int64
To this:
cereal['fat'] * 1000
0 1000
1 5000
2 1000
3 0
4 2000
Name: fat, dtype: int64
See how each value has changed?
Note that when we do any type of operations on columns, we use single square brackets.
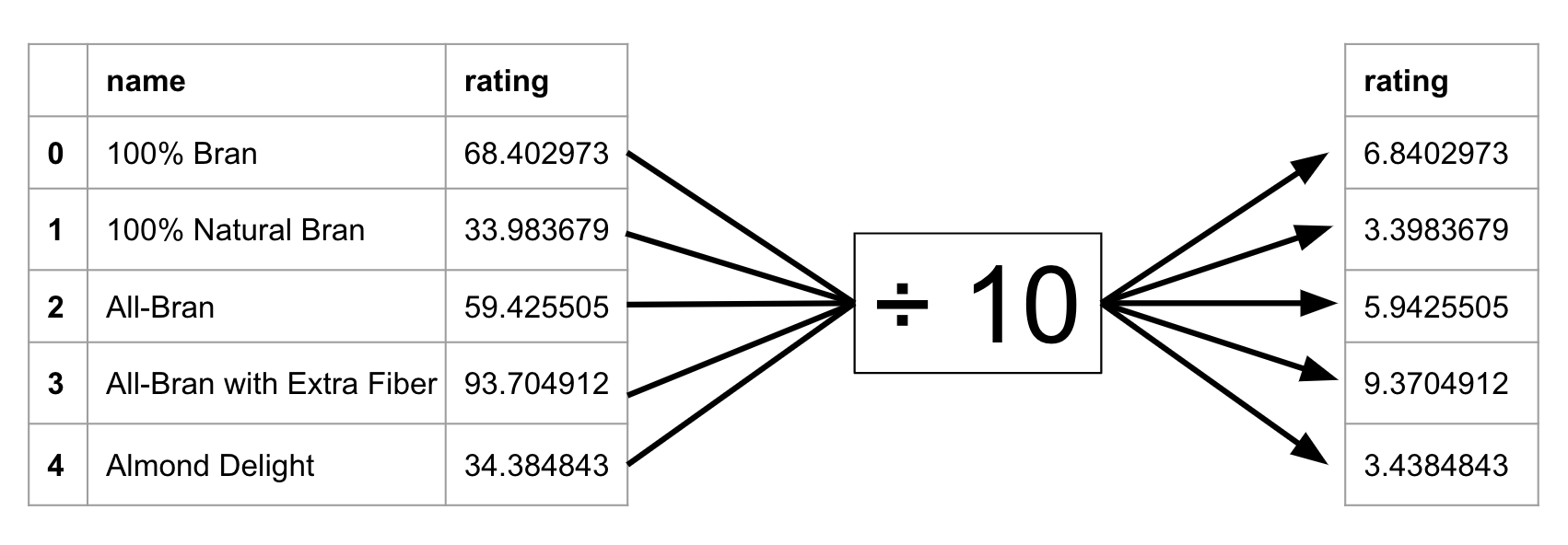
We can do the same thing with most operations. Let’s divide the rating of each cereal by 10 so that it lies on a 10 point scale.
cereal['rating']
0 68.402973
1 33.983679
2 59.425505
3 93.704912
4 34.384843
Name: rating, dtype: float64
The ratings column gets transformed to single digits instead of double digits now.
cereal['rating'] / 10
0 6.840297
1 3.398368
2 5.942551
3 9.370491
4 3.438484
Name: rating, dtype: float64
Every row’s value is changed by the operation.
We are not limited to simply taking a column and transforming it by a single number, say by multiplying or dividing.
We can do operations involving multiple columns as well. Perhaps we
wanted to know the amount of sugar (sugar) per cup of cereal (cups).
The expected result would look something like this diagram.
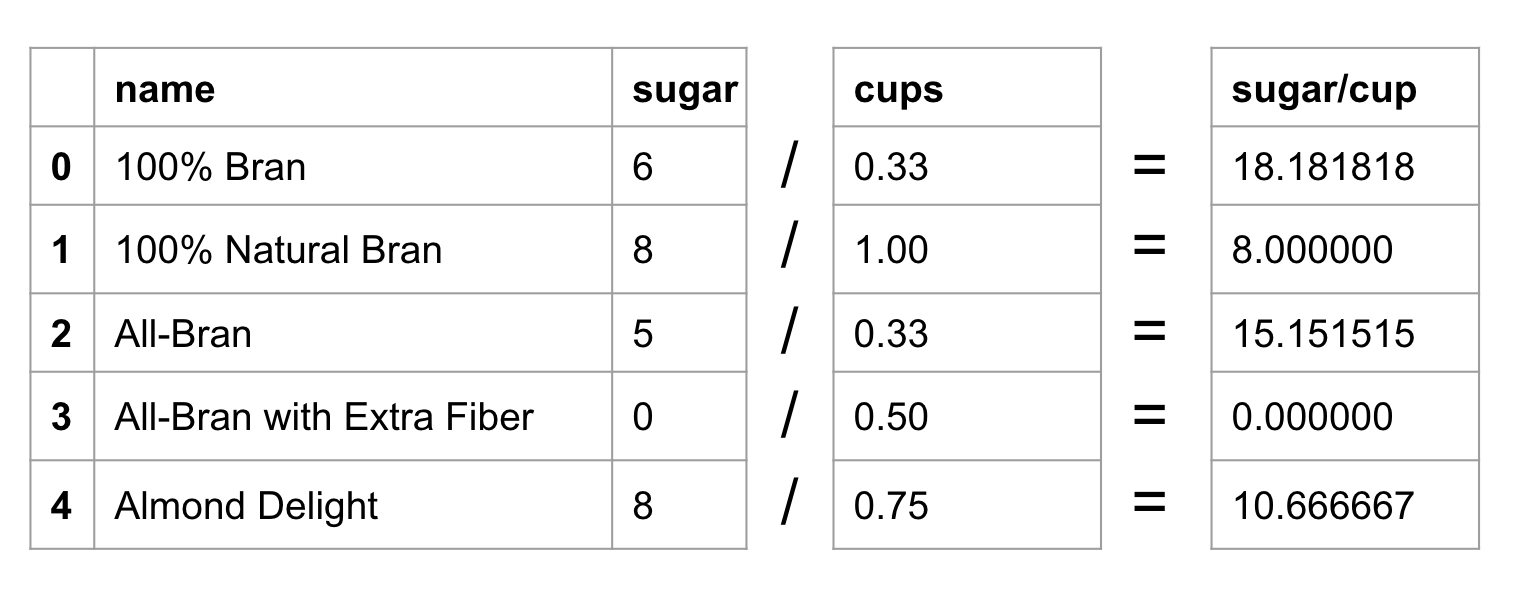
To get our desired output of sugar content per cup our code looks like this.
cereal['sugars'] / cereal['cups']
0 18.181818
1 8.000000
2 15.151515
3 0.000000
4 10.666667
dtype: float64
Remember that with any column operation we use only single square brackets on our columns.
Each sugar row value is divided by its corresponding cups value.
Just to stress the point of why we use single square brackets for our operations, here is what happens when we use double square brackets.
cereal[['sugars']] / cereal[['cups']]
| cups | sugars | |
|---|---|---|
| 0 | NaN | NaN |
| 1 | NaN | NaN |
| 2 | NaN | NaN |
| 3 | NaN | NaN |
| 4 | NaN | NaN |
This doesn’t appear very useful.
Column Creation¶
Up until now, all of these operations have been done without being added to our cereal dataframe.
Let’s explore how we can add new columns to a less detailed version of our cereal dataframe.
We’ll be working with a smaller dataframe containing only a few columns columns so that it’s easier to follow the examples.
cereal = pd.read_csv('cereal.csv', usecols=['name', 'mfr','type', 'fat', 'sugars', 'weight', 'cups','rating'])
cereal
| name | mfr | type | fat | sugars | weight | cups | rating | |
|---|---|---|---|---|---|---|---|---|
| 0 | 100% Bran | N | Cold | 1 | 6 | 1.0 | 0.33 | 68.402973 |
| 1 | 100% Natural Bran | Q | Cold | 5 | 8 | 1.0 | 1.00 | 33.983679 |
| 2 | All-Bran | K | Cold | 1 | 5 | 1.0 | 0.33 | 59.425505 |
| 3 | All-Bran with Extra Fiber | K | Cold | 0 | 0 | 1.0 | 0.50 | 93.704912 |
| 4 | Almond Delight | R | Cold | 2 | 8 | 1.0 | 0.75 | 34.384843 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 72 | Triples | G | Cold | 1 | 3 | 1.0 | 0.75 | 39.106174 |
| 73 | Trix | G | Cold | 1 | 12 | 1.0 | 1.00 | 27.753301 |
| 74 | Wheat Chex | R | Cold | 1 | 3 | 1.0 | 0.67 | 49.787445 |
| 75 | Wheaties | G | Cold | 1 | 3 | 1.0 | 1.00 | 51.592193 |
| 76 | Wheaties Honey Gold | G | Cold | 1 | 8 | 1.0 | 0.75 | 36.187559 |
77 rows × 8 columns
In the next scenario, we have decided that our weight column should
show the weight of each cereal in grams instead of ounces.
We are going to save the conversion factor of grams to ounces in an
object named oz_to_g.
Let’s start with just the operation for this.
oz_to_g = 28.3495
cereal['weight'] * oz_to_g
0 28.3495
1 28.3495
2 28.3495
3 28.3495
4 28.3495
...
72 28.3495
73 28.3495
74 28.3495
75 28.3495
76 28.3495
Name: weight, Length: 77, dtype: float64
Next, we combine our operation with the implementation of adding it as a
new column to the dataframe. The verb .assign() allows us to specify a
column name to our result using an equal sign =.
We are going to name our new column weight_g (for grams).
Just like we did earlier in the module, we need to save the dataframe to
an object when making changes involving columns. This will permanently
save the column weight_g to the dataframe cereal.
cereal = cereal.assign(weight_g=cereal['weight'] * oz_to_g)
cereal.head()
| name | mfr | type | fat | sugars | weight | cups | rating | weight_g | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 100% Bran | N | Cold | 1 | 6 | 1.0 | 0.33 | 68.402973 | 28.3495 |
| 1 | 100% Natural Bran | Q | Cold | 5 | 8 | 1.0 | 1.00 | 33.983679 | 28.3495 |
| 2 | All-Bran | K | Cold | 1 | 5 | 1.0 | 0.33 | 59.425505 | 28.3495 |
| 3 | All-Bran with Extra Fiber | K | Cold | 0 | 0 | 1.0 | 0.50 | 93.704912 | 28.3495 |
| 4 | Almond Delight | R | Cold | 2 | 8 | 1.0 | 0.75 | 34.384843 | 28.3495 |
Let’s try another example.
This time we want to save our sugar content per cereal cup as a column in our existing dataframe.
Here, you can see the operation by itself, just for teaching purposes.
cereal['sugars'] / cereal['cups']
0 18.181818
1 8.000000
2 15.151515
3 0.000000
4 10.666667
...
72 4.000000
73 12.000000
74 4.477612
75 3.000000
76 10.666667
Length: 77, dtype: float64
Below, we combine our calculation with assign(),
naming the column sugar_per_cup.
cereal = cereal.assign(sugar_per_cup=cereal['sugars'] / cereal['cups'])
cereal.head()
| name | mfr | type | fat | sugars | weight | cups | rating | weight_g | sugar_per_cup | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100% Bran | N | Cold | 1 | 6 | 1.0 | 0.33 | 68.402973 | 28.3495 | 18.181818 |
| 1 | 100% Natural Bran | Q | Cold | 5 | 8 | 1.0 | 1.00 | 33.983679 | 28.3495 | 8.000000 |
| 2 | All-Bran | K | Cold | 1 | 5 | 1.0 | 0.33 | 59.425505 | 28.3495 | 15.151515 |
| 3 | All-Bran with Extra Fiber | K | Cold | 0 | 0 | 1.0 | 0.50 | 93.704912 | 28.3495 | 0.000000 |
| 4 | Almond Delight | R | Cold | 2 | 8 | 1.0 | 0.75 | 34.384843 | 28.3495 | 10.666667 |
Let’s apply what we learned!
1. What is the result if we multiply 2 columns together using the syntax
df[['Column_A']] * df[['Column_B']]
a) A new column in our dataframe with each column value multiplied together for each row.
b) A single column with each column value multiplied together for each row.
c) A dataframe containing 2 new columns with NaN values.
2. What is the correct syntax to multiply Column_A and Column_B from dataframe df and save it as a new column named new_column?
a) df = df.assign('new_column'=df['Column_A'] * df['Column_B'])
b) df = df.assign(new_column=df['Column_A'] * df['Column_B'])
c) df = df.assign[new_column=df('Column_A') * df('Column_B')]
Solutions!
c) A dataframe containing 2 new columns with
NaNvalues.b)
df = df.assign(new_column=df['Column_A'] * df['Column_B'])