Reading in Different File Types¶
Watch it
See the accompanied youtube video at the link here.
Reading in Different File Types¶
In the last module, we learned how to read in a csv file but loading
in data is not restricted to this file type.
pandas facilitates the loading of data from many different file types
including::
A URL: If the data is stored publicly on a webpage, pandas can read it directly in from the page address.
A
txtfile: We saw what a plain text file looked like in the last module and it is generally a simple manner of storing data.An
xlsxfile: This is a Microsoft Excel spreadsheet. This is different than a regularcsvfile as an Excel file can contain many different sheets and can be formatted uniquely and specifically for an individual’s needs.
Of course, there are many other file types but we will focus on these for this course.
Reading from a URL¶
If the data is accessible publicly on a website, you can read in data directly from the webpage it is stored on. For example, this code and all the files that make up this course are all openly available and can be viewed online.
The candybar.csv file that we used in the last module, is stored at
this URL.
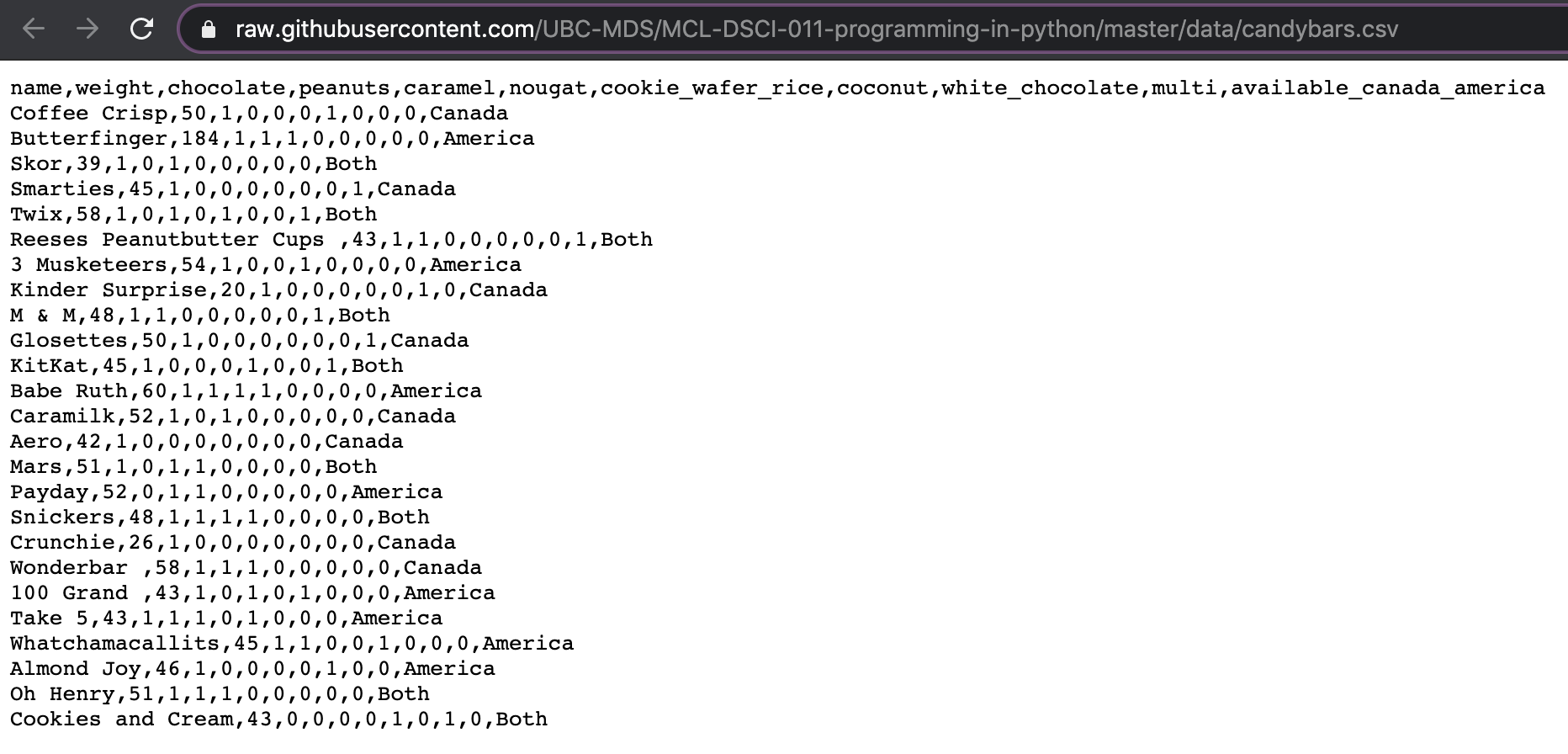
You can see that it looks like a plain text file with each line being a row and each column value separated with a comma.
The code required to read in this URL looks like this.
candybars = pd.read_csv('https://raw.githubusercontent.com/UBC-MDS/MCL-DSCI-511-programming-in-python/master/data/candybars.csv')
candybars.head()
| name | weight | chocolate | peanuts | caramel | nougat | cookie_wafer_rice | coconut | white_chocolate | multi | available_canada_america | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Coffee Crisp | 50 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | Canada |
| 1 | Butterfinger | 184 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | America |
| 2 | Skor | 39 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | Both |
| 3 | Smarties | 45 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | Canada |
| 4 | Twix | 58 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | Both |
It uses the same pd.read_csv() function we saw when reading in csv
files locally.
Reading in a Text File¶
Reading in txt files can be a little less standard.
Sometimes the character separating column values are not always commas like we saw before.
There are many different options and when we read in the data, we need to specify how the data should be recognized.
Let’s load in the candybars-text.txt file.
This is the same as the candybars.csv data but saved as a txt file.
Look what happens when we load it in using the same syntax we are used to.
candybars = pd.read_csv('candybars-text.txt')
candybars.head()
| name\tweight\tchocolate\tpeanuts\tcaramel\tnougat\tcookie_wafer_rice\tcoconut\twhite_chocolate\tmulti\tavailable_canada_america | |
|---|---|
| 0 | Coffee Crisp\t50\t1\t0\t0\t0\t1\t0\t0\t0\tCanada |
| 1 | Butterfinger\t184\t1\t1\t1\t0\t0\t0\t0\t0\tAme... |
| 2 | Skor\t39\t1\t0\t1\t0\t0\t0\t0\t0\tBoth |
| 3 | Smarties\t45\t1\t0\t0\t0\t0\t0\t0\t1\tCanada |
| 4 | Twix\t58\t1\t0\t1\t0\t1\t0\t0\t1\tBoth |
This is not ideal.
What you should notice is instead of each column value being separated
by a comma, it is now separated by \t.
This is called the delimiter.
In this specific case, a \t delimiter is a “tab”.
We need to tell pd.read_csv() to separate each value on our delimiter
\t.
candybars = pd.read_csv('candybars-text.txt', delimiter='\t')
candybars.head()
| name | weight | chocolate | peanuts | caramel | nougat | cookie_wafer_rice | coconut | white_chocolate | multi | available_canada_america | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Coffee Crisp | 50 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | Canada |
| 1 | Butterfinger | 184 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | America |
| 2 | Skor | 39 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | Both |
| 3 | Smarties | 45 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | Canada |
| 4 | Twix | 58 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | Both |
That’s much better.
The delimiter won’t always be \t for txt files. The most common
delimiters are ;, ,, \t, and sometimes even just spaces.
Reading in an Excel File (xlsx)¶
Excel files need special attention because they give the user the capability of additional formatting including saving multiple dataframes on different “sheets” within a single file.
If this is the case, we need to specify which sheet we want.
Since this is a new type of animal, we also need a new verb. Enter
read_excel().
Our candybars dataframe is now saved as an excel spreadsheet named
foods.xlsx on a sheet named chocolate.
Here is how we would read it in.
candybars = pd.read_excel('foods.xlsx', sheet_name='chocolate')
candybars
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
/tmp/ipykernel_1908/3686699700.py in <module>
----> 1 candybars = pd.read_excel('foods.xlsx', sheet_name='chocolate')
2 candybars
~/python3.7/lib/python3.7/site-packages/pandas/util/_decorators.py in wrapper(*args, **kwargs)
309 stacklevel=stacklevel,
310 )
--> 311 return func(*args, **kwargs)
312
313 return wrapper
~/python3.7/lib/python3.7/site-packages/pandas/io/excel/_base.py in read_excel(io, sheet_name, header, names, index_col, usecols, squeeze, dtype, engine, converters, true_values, false_values, skiprows, nrows, na_values, keep_default_na, na_filter, verbose, parse_dates, date_parser, thousands, comment, skipfooter, convert_float, mangle_dupe_cols, storage_options)
362 if not isinstance(io, ExcelFile):
363 should_close = True
--> 364 io = ExcelFile(io, storage_options=storage_options, engine=engine)
365 elif engine and engine != io.engine:
366 raise ValueError(
~/python3.7/lib/python3.7/site-packages/pandas/io/excel/_base.py in __init__(self, path_or_buffer, engine, storage_options)
1231 self.storage_options = storage_options
1232
-> 1233 self._reader = self._engines[engine](self._io, storage_options=storage_options)
1234
1235 def __fspath__(self):
~/python3.7/lib/python3.7/site-packages/pandas/io/excel/_openpyxl.py in __init__(self, filepath_or_buffer, storage_options)
519 passed to fsspec for appropriate URLs (see ``_get_filepath_or_buffer``)
520 """
--> 521 import_optional_dependency("openpyxl")
522 super().__init__(filepath_or_buffer, storage_options=storage_options)
523
~/python3.7/lib/python3.7/site-packages/pandas/compat/_optional.py in import_optional_dependency(name, extra, errors, min_version)
116 except ImportError:
117 if errors == "raise":
--> 118 raise ImportError(msg) from None
119 else:
120 return None
ImportError: Missing optional dependency 'openpyxl'. Use pip or conda to install openpyxl.
Reading in Data from a Different File¶
Something you have seen in Module 1’s exercises is that when reading in
the data there is always a data/ before the file name.
This is because we are running the current code in a file that is located in a different folder than the data.
The data is specifying a folder in our current directory (folder).
We need to specify the path to the csv file through the subdirectory.
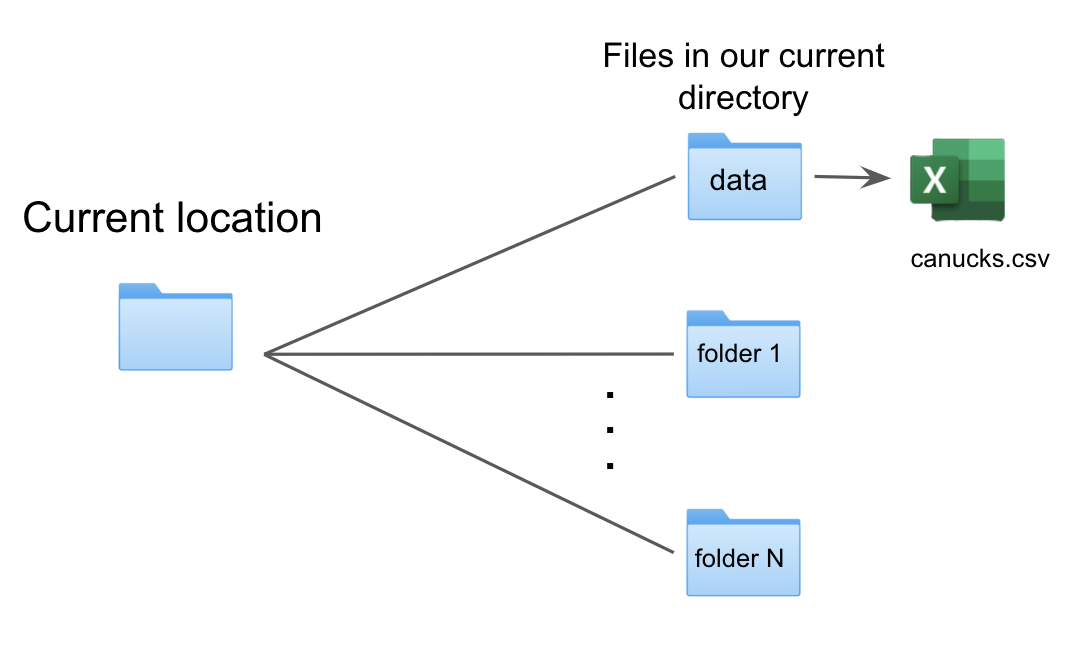
This translates to the syntax data/canucks.csv.
This syntax is not restricted to a single subdirectory and could even have multiple folders between the current location and the final file name.
Example:
data/module3/question2/candybars.csv

You can see the whole course structure and it’s subdirectories openly online.
In this course, we save all our data in a folder called data so when
asked to read in data, take care in future exercises to add the full
path to the required file.

It may be a good idea to look in the data folder to see exactly where the data you are loading in the exercises is coming from.
Let’s apply what we learned!
1. What is a delimiter?
a) It defines how column values are separated
b) It prevents a limitation on the data being read it
c) It is a manner of deleting values from a dataframe
2. What argument is needed if we want to read in data from an Excel spreadsheet where there is data saved on different sheets?
a) header
b) sheet_name
c) sheet
Solutions!
a) It defines how column values are separated
b)
sheet_name